Transactional Databases
The Engine Behind Every Application
I've been thinking about data architecture lately, specifically how different systems serve different purposes. Every application I've built has relied on a transactional database somewhere in the stack. When a user updates their profile, places an order, or transfers money, a transactional database ensures the operation completes reliably. These systems, also called Online Transaction Processing (OLTP) databases, form the backbone of modern software.
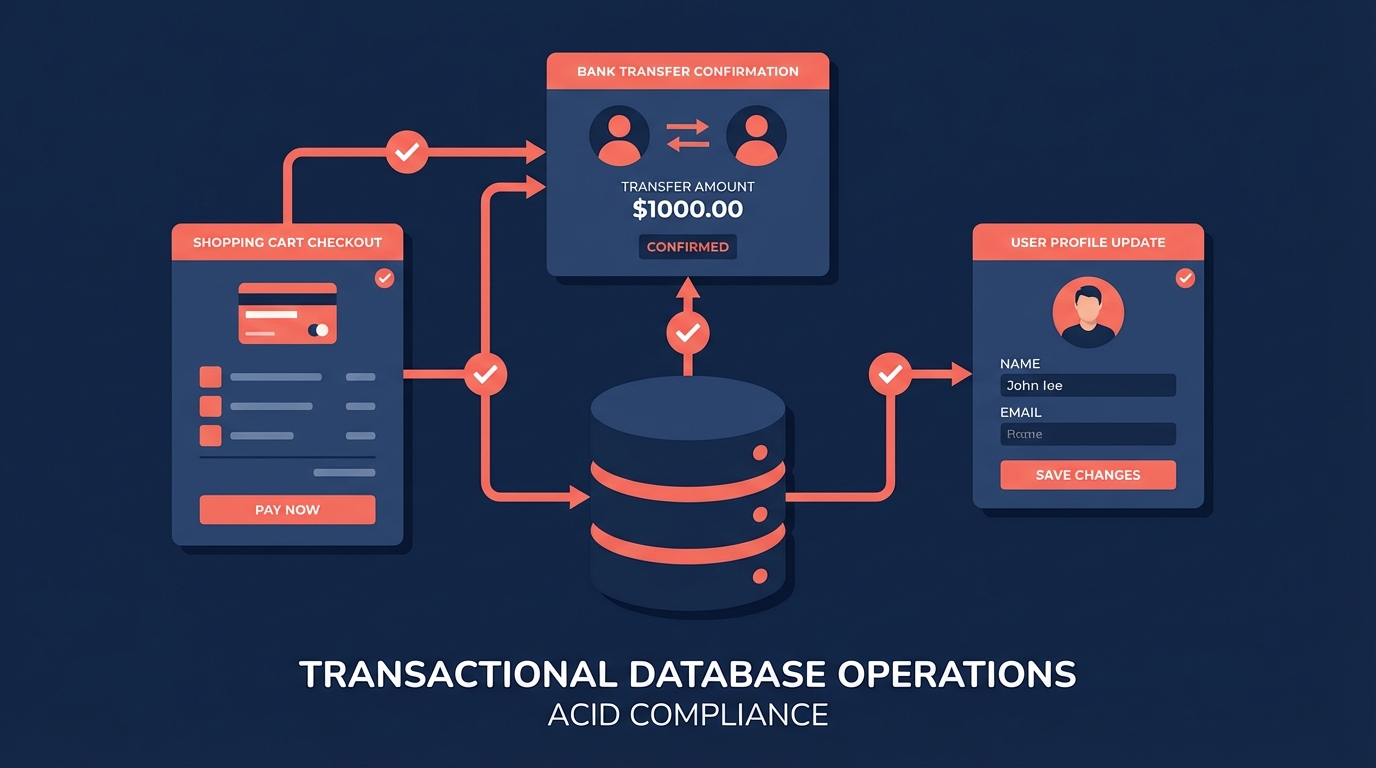
The defining feature of transactional databases is their adherence to ACID properties: Atomicity, Consistency, Isolation, and Durability. Atomicity means a transaction either completes entirely or not at all. Consistency ensures the database moves from one valid state to another. Isolation keeps concurrent transactions from interfering with each other. Durability guarantees that once a transaction commits, it stays committed even if the system crashes.
Relational vs NoSQL
Transactional databases come in two main flavors, and understanding when to use each has saved me from a lot of architectural headaches.
Relational databases structure data into tables with rows and columns, bound by predefined schemas. They use SQL for querying and excel at complex joins between related data. PostgreSQL, MySQL, and SQL Server are common examples. Data is often normalized to reduce redundancy, which keeps storage efficient but can require multiple table joins for common queries.
NoSQL databases take a different approach. They offer flexibility for unstructured or semi-structured data without rigid schemas. Depending on the type, they might store documents (MongoDB), key-value pairs (Redis), wide columns (Cassandra), or graph relationships (Neo4j). NoSQL databases are typically designed for horizontal scaling, distributing data across multiple servers to handle high traffic. The tradeoff is that they often follow the CAP theorem, sacrificing some consistency guarantees in exchange for availability and partition tolerance.
When to Use Each
The choice between relational and NoSQL depends on your data and access patterns. Relational databases work well when your data has clear relationships, when you need complex queries across multiple entities, or when consistency is critical. Banking systems, inventory management, and CRM platforms typically use relational databases because data integrity matters more than raw throughput.
NoSQL databases shine when you're dealing with high write volumes, when your data structure evolves frequently, or when you need to scale horizontally across servers. Social media feeds, real-time analytics, and caching layers often use NoSQL because flexibility and speed outweigh the need for strict consistency.
Most production systems I've worked on use both. A relational database handles core business data while a Redis cache accelerates frequent reads. Understanding the strengths of each helps us put them to work where they fit best.
In the next post, we'll look at data warehouses, which solve a different problem entirely: analyzing historical data at scale.