Data Lakes and Choosing the Right System
Raw Data Storage and When to Use What
In the previous posts, I covered transactional databases for real-time operations and data warehouses for historical analytics. Both work with structured data. But what happens when you need to store log files, images, sensor readings, or raw event streams? That's where data lakes come in, and understanding them has changed how I think about data architecture.
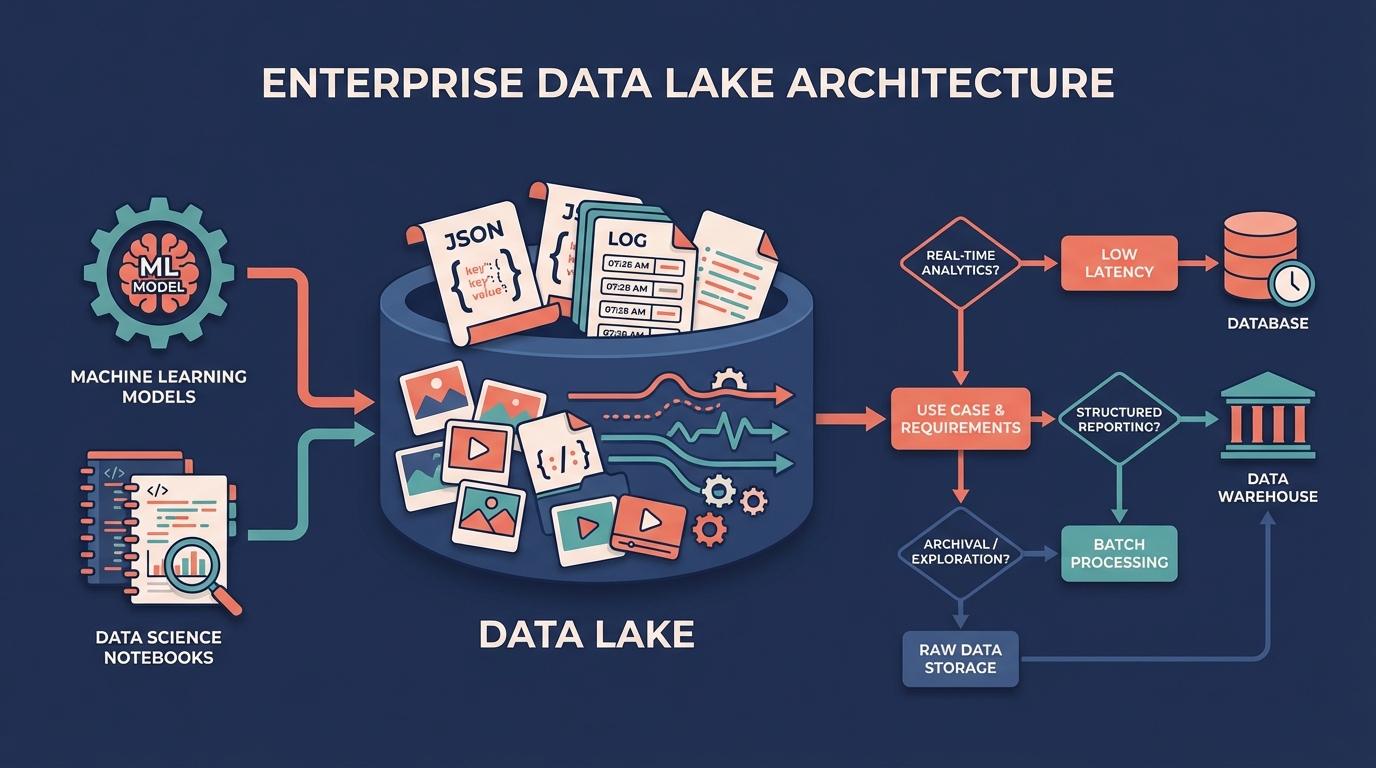
A data lake is a centralized repository that stores data in its raw, native format. Unlike warehouses that require transformation before loading, data lakes ingest data as-is. This makes them ideal for situations where you don't yet know how you'll analyze the data, or when you want to preserve the original format for machine learning workloads that need access to raw features.
Schema-on-Read
Data lakes use a schema-on-read approach, the opposite of data warehouses. Instead of defining structure before loading, you apply structure when you query. This flexibility means you can store anything: JSON logs, CSV exports, Parquet files, images, video. When it's time to analyze, you define the schema that makes sense for that particular query.
The tradeoff is that data lakes can become disorganized without proper governance. I've seen this happen: when anyone can dump any format into the lake without documentation or standards, finding and using data becomes difficult. The industry term for this failure mode is "data swamp," and it's common in organizations that adopt data lakes without clear ownership and cataloging practices.
Big Data and Machine Learning
Data lakes shine in big data scenarios. They're designed to scale to petabytes, handling the volume that modern data collection produces. They integrate well with distributed processing frameworks that can parallelize computation across clusters. For machine learning projects, data scientists often need access to raw data to engineer features, and data lakes provide that access without the constraints of a predefined schema.
Choosing the Right System
After working with all three, I see them this way. These systems aren't competing alternatives. They serve different purposes and often work together in a mature data infrastructure. Transactional databases collect data through application operations. That data flows to warehouses for business analytics and to lakes for data science and big data workloads.
When deciding where to invest, consider your primary use case. If you need real-time operations with strong consistency, start with a solid transactional database setup. If your business runs on reports, dashboards, and historical analysis, prioritize a data warehouse. If you're building machine learning pipelines or dealing with high volumes of varied data types, a data lake makes sense.
Volume matters too. Petabytes of mixed data types point toward a data lake. Terabytes of structured business data work well in a warehouse. Gigabytes of operational data fit in a transactional database. Budget also plays a role: transactional databases have lower initial costs, while warehouses and lakes require more infrastructure and expertise to operate well.
Most organizations eventually need all three. The key is understanding what each system does well and putting data where it can be used most effectively. A clear data strategy that defines how data flows between systems prevents duplication, reduces costs, and ensures that analysts and applications always have access to the data they need.